 Table of Contents
Table of Contents  Previous Section
Previous Section
Note: To support the toJobTitle relationship, the Employee entity has been altered-the titleID attribute has been added to it. This is explained in the section "Relationship Keys".
Be aware that you can't just randomly create relationships between your entities. Relationships that you add to your entities must reflect real relationships between the tables in the database. For more information, see the section "Relationship Keys".
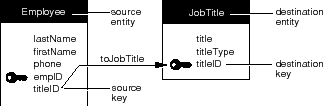
Figure 57. The toJobTitle Relationship
Unidirectionality is enforced by the way a relationship is resolved. Specifically, the source record is a given. Resolving a relationship means finding the correct destination record (or records) given a specific source record.
Bidirectional relationships-in which you can look up records in either direction-can be created by adding a separate "return-trip" relationship. This is demonstrated in the section "Bidirectional Relationships".
In the figures throughout this book, the entity that is adjacent to the relationship's label is said to own the relationship. For example, in Figure 57 the Employee entity owns the toJobTitle relationship, as indicated by the proximity of the "toJobTitle" label to the entity.
The reason you need to designate relationship keys is so the relationship can be used to create cross-references between specific instances of the related entities (this is called "resolving" the relationship). For example, let's say you fetch an employee object. The Enterprise Objects Framework takes the value for the employee's titleID attribute and compares it to the value for titleID in each JobTitle instance. A match locates the desired job title record.
For this cross-referencing scheme to work, the source and destination keys must characterize the same data-you couldn't find an employee's job title by comparing, for example, Employee.empID to JobTitle.titleID. This is why the titleID attribute was added to the Employee entity.
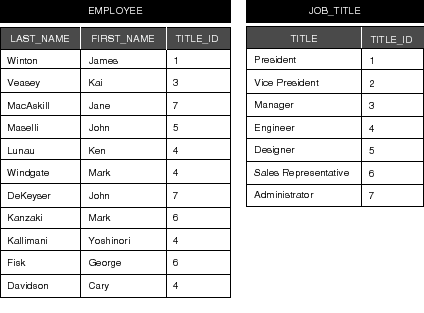
Figure 58. The "EMPLOYEE" and "JOB_TITLE" Tables
Note that if empID had been used as the relationship key for the toJobTitle relationship, a given title could only be assigned to a single employee.
For example, consider an entity (empPhoto) containing the employee's picture that uses the attributes firstName and lastName as a compound relationship key. (Using people's names for unique identification is generally a bad idea, but it serves the purpose for illustration. In actual practice, this relationship would likely use empID as its relationship key.) This relationship is depicted in Figure 59.
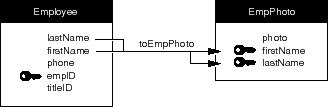
Figure 59. A Compound Relationship
The algorithm used to resolve a compound relationship is similar to that for a simple relationship. The only difference is the number of pairs of relationship key values that are compared. For two records to correspond, all of the comparisons must be successful.
Note: The keys in a compound relationship can be a combination of any attributes-not just a compound primary key (or foreign keys to a compound primary key). Conversely, you can use a single attribute from a compound primary key as a relationship key in a simple
(non-compound) relationship.
This switch does more than demonstrate that the same attributes can be used as relationship keys in more than one relationship; it also exemplifies the typical orientation of the primary key with regard to the relationship keys in to-one and to-many relationships:
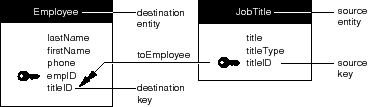
Consider, for example, the actual relationship between employees and projects. A project can involve many employees, and a single employee can contribute to more than one project.

Forming a to-many relationship between Employee and Project (toProject) and a to-many relationship between Project and Employee (toEmployee) doesn't work, because it's impossible to assign relationship keys that would support this set-up. For example, in the toProject relationship you can't use the empID attribute as a source key because the destination key, Project.empID (added as a foreign key), wouldn't be atomic (since a project may consist of more than one employee). Importing projectID as a foreign key into Employee has the same problem: The attribute wouldn't be atomic (since an employee may be involved with more than one project).
The most common way to establish this "many-to-many" relationship (as it's called in traditional E-R modeling) is to insert an auxiliary entity between Employee and Project, and form a network of relationships to and from it. This is depicted in Figure 62.
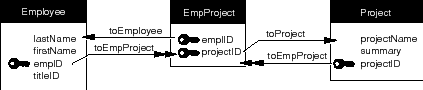
Figure 62. A Many-to-Many Relationship
The compound primary key used in EmpProject indicates that the entity characterizes unique combinations of employees and projects. The table that the entity represents would hold a different record for each employee of every project. For example, if three employees were involved with a single project, there would be three EmpProject instances with the same value for the projectID attribute, but each record would have a different value for its empID attribute.
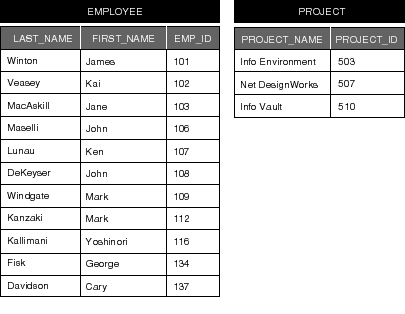
Figure 63. "EMPLOYEE" and "PROJECT" Tables
The "EMP_PROJECT" table is shown in Figure 64 (for clarity, the last names and project names are shown in the margins).
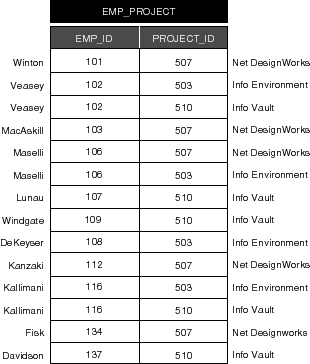
Figure 64. The "EMP_PROJECT" Table
As expected, some values appear more than once for the empID attribute; similarly, some values for projectID are repeated. But since empID and projectID form a compound primary key for the EmpProject entity, no two records may possess the same combination of values for these two attributes. This fact-that no two records can have the same empID and the same ProjectID-signifies that a given employee cannot be assigned to a single project more than once.
For example, to show who a given employee reports to, you could create a separate Manager entity. It would be easier, however, to just create a reflexive relationship, as shown in Figure 65.
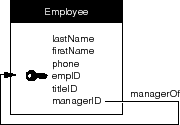
Figure 65. A Reflexive Relationship
Note: The name of the relationship, managerOf, doesn't follow the relationship naming convention suggested earlier in this chapter. However, it follows from the meaning of the relationship, and meaning takes precedence over form.
The managerID attribute acts as the relationship's source key; empID is the destination key. Where an employee's managerID matches another employee's empID, the first employee reports to the second. If an employee doesn't have a manager, the value for the managerID attribute is NULL in that employee's record.
Reflexive relationships can represent arbitrarily deep recursions. Thus, from the model above, an employee can report to another employee who reports to yet another employee, and so on. This could go on until an employee who's managerID is NULL is reached, denoting an employee who reports to no one (probably the company president!).
A flattened attribute is an attribute that you effectively add from one entity to another by traversing a relationship. You can't add arbitrary attributes from various entities, however. To add an attribute from one entity to another, there must be a to-one relationship between those entities.
For example, by traversing the toJobTitle relationship, you can determine a given employee's title. If you add the title attribute from the JobTitle entity to the Employee entity as a flattened attribute, the Enterprise Objects Framework will automatically traverse the relationship and locate the employee's title when the employee is fetched from the database.
To your code, the flattened attribute looks like any other. After adding the title attribute to the Employee entity as a flattened attribute (which has no effect on the "EMPLOYEE" table in the database), for instance, your application's view of the Employee table would look like Figure 66:
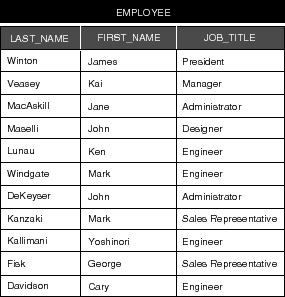
Figure 66. A View of the "EMPLOYEE" Table After Adding a Flattened Attribute
You are not limited to flattening attributes across a single relationship; any number of relationship traversals can be employed. Thus, if there was a relationship between the JobTitle entity and a SalaryRange entity, you could include an employee's maximum salary with the rest of the employee information by flattening a toJobTitle.toSalaryRange.maxSalary attribute into the Employee entity.
As an example, suppose you need department information for corporate assets that are assigned to employees, using the entities and relationships shown in Figure 67. One way to obtain the needed information is to flatten the relevant attributes (deptName and location, perhaps) across the toEmployee and toDepartment relationships. A simpler way would be to flatten the toDepartment relationship itself, so that it appears to your code as if the Department entity is a part of the Equipment entity.

Figure 67. Equipment Allocated by Department
Figure 68 shows how the Equipment entity might look after the flattened relationship had been added. In it, toDepartment is a relationship defined as toEmployee.toDepartment. When your code asks an Equipment object for the value of its toDepartment property, it receives the corresponding Department object. Your code can then query the Department object for the needed properties.

Figure 68. A Flattened Relationship
While the entities involved in a flattened relationship must be related, those relationships can either be to-one or to-many. If any of the relationships are to-many and your code requests the value for a flattened relationship, it will receive an array of objects corresponding to the flattened relationship's destination entity.